1 Hiera Refactoring¶
1.1 New Hierarchy¶
We believe that there was general consensus during discussions at the start of the puppeton that the current hierarchy was difficult to use and in need of refactoring.
1 2 3 4 5 6 7 8 9 | - "%{country}/%{site}/%{enclave}/%{datacenter}/%{cluster}/%{networking.hostname}.yaml"
- "%{country}/%{site}/%{enclave}/%{datacenter}/%{cluster}/%{cluster}.yaml"
- "%{country}/%{site}/%{enclave}/%{datacenter}/%{datacenter}.yaml"
- "%{country}/%{site}/%{enclave}/%{enclave}.yaml"
- "%{country}/%{site}/%{site}.yaml"
- "%{country}/%{country}.yaml"
- "type/%{virtual}.yaml"
- "type/default.yaml"
- "common.yaml"
|
1.1.1 identified defects with existing structure¶
- The structure is nested 6 levels deep, which is too complex for current needs. E.g.,
us/po/gs/po/puppet/gs-puppet-master.yaml - It contains plain text secrets.
%{networking.hostname}.yamland%{cluster}.yamlmatch at the same level!- With the exception of type, there are no ‘parent’ directories to aid an editing engineer in navigating the path structure.
- There are no layers matching a
role, which does not mesh well with the well known roles and profiles pattern pattern, this is intended to berolecentric. - Almost all hiera keys are not namespaced (
foo::<key>) and manually retrieved from puppet code usinglookup(). This makes it difficult to determine which, if any, profile class is using that data.
1.1.2 revised hierarchy¶
In an effort to simplify overall Hiera usage, we worked on migrating to this revised new hierarchy:
1 2 3 4 5 6 7 8 9 10 11 12 | - "node/%{fqdn}.yaml"
- "site/%{site}/cluster/%{cluster}/role/%{role}.yaml"
- "site/%{site}/cluster/%{cluster}.yaml"
- "cluster/%{cluster}/role/%{role}.yaml"
- "cluster/%{cluster}.yaml"
- "site/%{site}/role/%{role}.yaml"
- "site/%{site}.yaml"
- "role/%{role}.yaml"
- "role/%{role}/type/%{virtual}.yaml"
- "type/%{virtual}.yaml"
- "type/default.yaml"
- "common.yaml"
|
As the result of some inputs & agreements:
countryandenclaveare not necessary, since we are already classifying locations usingsite.- Most of the current definitions seem to be role-specific, instead of node-specific.
- Data lookup - by default - will search the hierarchy in the order defined and return the first value found. Thus, the order is always specified from most specific to least specific.
typewas added to facilitate refactoring the existing hierarchy but the name feels awkward and should be revisited.
Example of new directory structure (filtered down to a single site and a handful of roles):
.
├── cluster
│ └── comcam.yaml
├── common.yaml
├── role
│ ├── cc_camera.yaml
│ ├── cc_daq.yaml
│ ├── cc_diag.yaml
│ ├── grafana.yaml
│ ├── graylog.yaml
│ ├── influxdb.yaml
│ └── puppet_master.yaml
├── site
│ ├── po
│ │ └── role
│ │ ├── graylog.yaml
│ │ ├── influxdb.yaml
│ │ └── puppet_master.yaml
│ └── po.yaml
└── type
├── default.yaml
└── physical.yaml
1.1.3 General usage guidelines¶
- The emphasis should be on configuration by role.
- Data should be only present when it will actually be used. As an example, it is possible to configure most role data, where it does not conflict, in
common.yaml. While keys are unmatched are harmlessly ignored, this tends to obscure which data is actually being used. - Role data should be added at the least specific layer possible that does not cause said data to become visible to an unrelated role. TL;DR - start at
roleunless it is globally needed data. - The
role,site, andclusternames need to be globally unique. E.g., there may not be a cluster namedfooat different sites with different functions. - Data should be aggressively curated and removed if not actively used.
- The hierarchy should be considered more of a logical construct rather than a physical representation. For example,
siteneed not be a literal physical locale but could represent any high level logical grouping of hosts. - Ideally,
nodeshould never be used. - Do not add layers in advance of usage. I.e., differ complexity until it is needed
- Do not consider the hierarchy as rigid – refactor as warranted
1.1.4 Decouple node FQDN from hierarchy layers¶
The current hierarchy is dependent upon facts generated by parsing the node’s FQDN.
if len(hostname_list) >= 3:
data["enclave"] = hostname_list[2]
There are two issues with this approach that cause us to recommend rejecting it.
- It causes the hierarchy to be tightly coupled with the host name. A consequence of that relationship is that even minor refactoring of the hierarchy may require changing of hostnames. This is particularly inconvenient without an automated means of re-provisioning hosts.
- There is the risk that the host, either maliciously or by accident, returns facts that classify it with the incorrect role. We find that it is preferable to assign most critical hierarchy matching facts via ENC.
1.1.5 Viva la ENC¶
The existing custom ENC and associated “database repos”:
- https://github.com/LSST-IT/puppet-enc
- https://github.com/LSST-IT/cl_puppet_nodes_database
- https://github.com/LSST-IT/lsst-sandbox-nodes-database
- https://github.com/LSST-IT/ccs_puppet_nodes_database
essentially provides a mapping between a hostname matching regex and a puppet role class. Although the ENC appears to have been deployed in La Serena and the “sandbox”, it was never functioning in Tucson (po). We created a database for po by copying the one for ls, added the necessary hiera configuration, and fixed some minor profile problems in order to test the ENC in a sandbox environment. Ultimately, we found the custom ENC both overly complex to configure and too rigid to support the injection of additional facts without refactoring. This does not seem worth while considering the limited functionality.
For initial testing, we replaced the custom ENV with a primitive shell script.
#!/bin/bash
cat <<END
---
classes:
- role::it::graylog
environment: IT_1141_hiera_redux
parameters:
cluster: gs
datacenter: po
site: po
role: graylog
END
and then switched to using custom facts as an interim solution onto the transition to new ENC is made.
mkdir -p /etc/facter/facts.d
cat > /etc/facter/facts.d/role.txt <<END
role=graylog
site=po
END
We recommend adopting TheForeman as a production ENC.
1.2 Secrets Management¶
The majority of data should be maintained in a single, shared Hiera repo that is available to everyone that wants to see, use or modify puppet modules. However, some data, primarily OS level configuration such as private SSH keys, is inappropriate for public consumption.
For that reason, we decided to host sensitive data in a private repo called lsst-puppet-hiera-private, which is not public and is configured to be read by R10K alongside lsst-puppet-hiera:
cachedir: "/var/cache/r10k"
sources:
control:
remote: "https://github.com/lsst-it/lsst-itconf"
basedir: "/etc/puppetlabs/code/environments"
lsst_hiera_private:
remote: "git@github.com:lsst-it/lsst-puppet-hiera-private.git"
basedir: "/etc/puppetlabs/code/hieradata/private"
lsst_hiera_public:
remote: "https://github.com/lsst-it/lsst-puppet-hiera.git"
basedir: "/etc/puppetlabs/code/hieradata/public"
Both repos have the same Hiera hierarchy (described above), but the private repo must be given priority so that public Hiera can’t override a private setting.
This is intended to be a transitional step towards completely removing inline secrets from hiera. The intent is that the ``-private`` repo will be removed and only a single public repo used for hiera data, once appropriate secret management infrastructure is in place.
1.3 Roles are defined via hiera¶
Role classes, E.g.., role::foo::bar, should not be present in the control repo. Instead, the ‘role’ should be defined by a list of class to be included in hiera.
Example of direct class inclusion from hiera role layer (role/bar.yaml):
---
classes:
- "profile::default"
- "profile::foo::bar"
As a role class should only ever be composed of include statements, this removes boilerplate and reduces the minimum number of files related to a role. It also is intended to shift the focus on configuration/composition into the hiera repo.
For the immediate future, profile classes should continue to be used, and only profile classes should be directly included via hiera. This restriction is intended to avoid developer confusion.
1.4 Use automatic class parameter lookup¶
lookup()should only be used in exception circumstances; the implementation of magic or an extreme case where data can’t easily be deduplicated by with hiera layers.- Typically, data should ‘flow’ from hiera to profile classes via parameters
- Configuration data for non-profile classes should generally not be passed through a profile and configured in code but instead be set directly in hiera.
As an example, the name of the tz would be set directly on the timezone
class.
---
timezone::timezone: "UTC"
1.5 TODO¶
- confirm with Tiago & Chile Team which hierarchies/profiles are unused (E.g. EFD)
- Check if EFD, ATS or CCS definitions are being used. This will eventually remove
datacenterhierarchy. - Remove
typehierarchies, blocked as the moment by telegraf definitions. - Secrets management
2 Roles & Profiles Refactoring¶
2.1 Pin module versions to Puppetfile¶
Puppet modules must be pinned to a specific version number (reference), in order to avoid unpredictable dependency resolution & upgrade issues during the lifetime of puppet agents. Due to the usage of r10k, a specific version string must be used instead of a version constraint expression. E.g., use 1.1.1 instead of ~> 1.1.0
forge 'https://forgeapi.puppetlabs.com'
mod 'aboe/chrony', '0.2.5'
mod 'crayfishx/firewalld', '3.4.0'
mod 'elastic/elasticsearch', '6.3.3'
mod 'elastic/elastic_stack', '6.3.1'
mod 'ghoneycutt/ssh', '3.61.0'
...
Please note that in the name of consistency, all modules are named using slash (/) as a namespace separator instead of underscore (_).
2.2 Git Flow on new Repos¶
We propose the following puppet code branching strategy:
masterbranch is the baseline & latest version of our code, but will not be used for deployments.<jira-ticket-id>/<short-description>topic branches will include the work for each feature, which are based frommasterand pushed intomastervia PR.productionbranch includes existing nodes deployed versions, using git tags.
More details can be found at: Puppet Development Workflow
2.3 Use stdlib¶
There are several useful functions available in stdlib. Using these functions may save development effort and improve code readability.
Consider this example from the profile::it::puppet_master class:
if $hiera_id_rsa_path and $hiera_id_rsa_path =~ /(.*\/)(.*\id_rsa)/ {
$base_path = $1
$dir = split($base_path, '/')
$filename = $2
...
which may essentially be replaced with the basename and ensure_resources functions.
if $hiera_id_rsa_path {
$dir = dirname($hiera_id_rsa_path)
$filename = basename($hiera_id_rsa_path)
...
2.4 Be aware of type autorequire¶
The existing roles and profiles contain many examples of file resources using the require meta-parameter to introduce a dependency upon the parent directory.
Consider this example:
file{ '/root/.ssh/known_hosts':
ensure => present,
require => File['/root/.ssh/']
}
this code is equivalent:
file{ '/root/.ssh/known_hosts':
ensure => present,
}
as the file type will autorequire the parent directory along with resources for the user and group.
2.5 declare data type of class parameters¶
The data type of every profile class parameter must be declared. This functions as a sanity check against hiera data type errors.
class profile::foo(
Variant[Hash[String, String], Undef] $bar = undef,
Stdlib::Absolutepath $baz = "/tmp/baz",
Stdlib::Ensure::Service = "running",
) {
2.6 Make heavy usage of the forge¶
Check the forge before writing a new module or a profile that is anything but a list of direct inclusions.
As an example, prefer:
include timezone
exec { 'set-timezone':
provider => 'shell',
command => '/bin/timedatectl set-timezone UTC',
returns => [0],
onlyif => "test -z \"$(ls -l /etc/localtime | grep -o UTC)\""
}
As a general rule, it should not be necessary to use exec to manage base os resources. Check the forge for a suitable module before resorting to exec resources.
2.7 Be aware that all puppet functions are parse order dependent¶
There are many examples of defined() being used. However, it is critical to be aware that all duplicate declarations of a resources must be similarly protected. Otherwise, catalog compilation may fail when the parse order changes. ensure_resources from stdlib should be preferred.
2.8 Profiles should not use conditional logic based on the hostname¶
if $::hostname =~ /puppet-master/ {
file{'/etc/ssh/puppet_id_rsa_key':
ensure => file,
mode => '0600',
content => lookup('puppet_ssh_id_rsa')
}
}else{
ssh_authorized_key { 'puppet-master':
ensure => present,
user => 'root',
type => 'ssh-rsa',
key => lookup('puppet_ssh_id_rsa_pub')
}
}
if $::node_name == 'influxdb' {
include efd::efd_writers
include efd::efd_influxdb
} elsif $::node_name == 'mysql' {
include efd::efd_writers
include efd::efd_mysql
} elsif $::node_name == 'writers' {
include efd::efd_writers
} else {
include efd
}
Profiles should not have conditional behavior based on the hostname as it breaks the ability to compose roles by simply including profiles.
2.9 CI Checks¶
A few TravisCI jobs have been added to Hiera repos, to run code quality checks:
- Yamllint: checks the validity of each yaml file in the repo, against rules like indentation, quotes or comments. Sample yamllint rules can be found in here, and sample CI job configurations for yamllint can be found in here.
- Markdownlint: checks the validity of each markdown file in the repo, again rules like line length, unused lines or inline HTML. Sample markdownlint rules can be found in here, and sample CI job configurations for markdownlint can be found in here.
lsst-puppet-hiera and lsst-puppet-hiera-private CI jobs statuses are exposed with a badge, at the beginning of each README file.
The control repo includes the above travis checks but adds sanity checks from several puppet and ruby linting tools.
See the .travis.yaml for details.
2.10 Tested setups¶
The new Hiera hierarchy (composed by two repos) has been tested in the following hosts, after setting up their facts manually in facts.d folder:
| Hostname | Service | Puppet Profile |
|---|---|---|
gs-puppet-master |
Puppet Master Tucscon | puppet_master.pp |
gs-grafana-node-01 |
Grafana | grafana.pp |
gs-graylog-node-01 |
Graylog | graylog.pp |
gs-influxdb-node-01 |
InfluxDB | influxdb.pp |
ats-shutter-hcu |
ats header service? | Not modified per @mareuter |
2.11 Style Guide(s)¶
2.11.1 Git commit messages¶
See https://developer.lsst.io/work/flow.html#appendix-commit-message-best-practices
2.11.2 Puppet code¶
We propose that the puppetlabs style guide be adopted for puppet code.
Note that class names are not fully qualified. E.g., foo::bar is now preferred over ::foo::bar.
2.11.3 YAML markup¶
- Indenting (2 spaces; lists are indented)
- double space quotes are used for all strings until single space is required because of escape sequences
- No space between key name and
: - Lists and maps/hashes/dicts/associative arrays use the intended multi-line form
- Role names use
_instead of- - Avoid useless headers/comments as stale/excessive comments are often worse than no-comment. E.g., It is not necessary to explain that
role/foo.yamlis thefoorole. - Boolean values are true and false (lowercase only)
site,role, andclusternames must be unique- Break comment lines at 80cols
- No dangling whitespace
2.11.4 Puppetfile¶
- treated as ruby code and linted by
rubocop - use
/instead of-in module names
2.12 TODO¶
- Remove remaining role classes
- Refactor all profiles classes
3 Comcam Servers Setup¶
3.1 Setup¶
As a Proof-of-Concept, a Foreman server has been set up in Tucson to manage puppet infrastructure for Comcam servers. Foreman is a service that allows to configure Puppet environments using a Web UI, and includes bare metal provisioning & automated configuration features, like:
- Host inventory.
- DHCP, DNS, TFTP and PXE boot services.
- Customizable operating system templates.
- Puppet master server.
- Puppet node classifier.
- Node auditing reports.
- Rest API, and linux CLI.
- IPMI integration.
3.2 Foreman installation¶
- explain what is included (DHCP, TFTP, PXE, Puppet Master, DNS, report processor), and if anything was installed manually before foreman
- explain manual installations (DNS)
- show the usage of foreman hammer
- explain OS, groups, organizations,… setups in foreman UI
- r10k manual setup
- smee webhook integration to automate r10k
- kickstart scripts customization
3.2.1 foreman-installer flags¶
foreman-installer \
--enable-foreman-proxy \
--foreman-proxy-tftp=true \
--foreman-proxy-tftp-servername=10.0.103.101 \
--foreman-proxy-dhcp=true \
--foreman-proxy-dhcp-interface=em1 \
--foreman-proxy-dhcp-gateway=10.0.103.1 \
--foreman-proxy-dhcp-nameservers="10.0.103.101" \
--foreman-proxy-dhcp-range="10.0.103.101 10.0.103.105" \
--foreman-proxy-dns=true \
--foreman-proxy-dns-interface=em1 \
--foreman-proxy-dns-zone=test \
--foreman-proxy-dns-reverse=103.0.10.in-addr.arpa \
--foreman-proxy-dns-forwarders=140.252.32.21 \
--foreman-proxy-foreman-base-url=https://comcam-fp01.test \
--enable-foreman-plugin-remote-execution \
--enable-foreman-proxy-plugin-remote-execution-ssh
howto - ssh run - puppet master ca
research - choria/salt/etc. for triggering agent runs at scale
3.3 Client setup¶
- basic BIOS/UEFI setup
- power on after powerloss
- no halt on error
- PXE boot
- record iDRAC BMC IP
- record iDRAC password printed on chassis pull out card
- (note that this entire process could be skipped if the BMC was given a static IP assignment via DHCP by recording the mac address from the packaging)
- iDRAC setup
- access over https
- collect MAC addresses of BMC and PXE interfaces
- trigger a PXE boot
3.4 r10k “gitops”¶
We feel that it is important to automate the deploy of hiera/code changes for several reasons:
- Pushing changes is receptive work that disrupts a development workflow
- Updating the code is surprisingly prone to human error – I think I pushed it…
- It ensures that the git repo is the true “source of truth” rather than the state of files on disk as of whenever they were last updated.
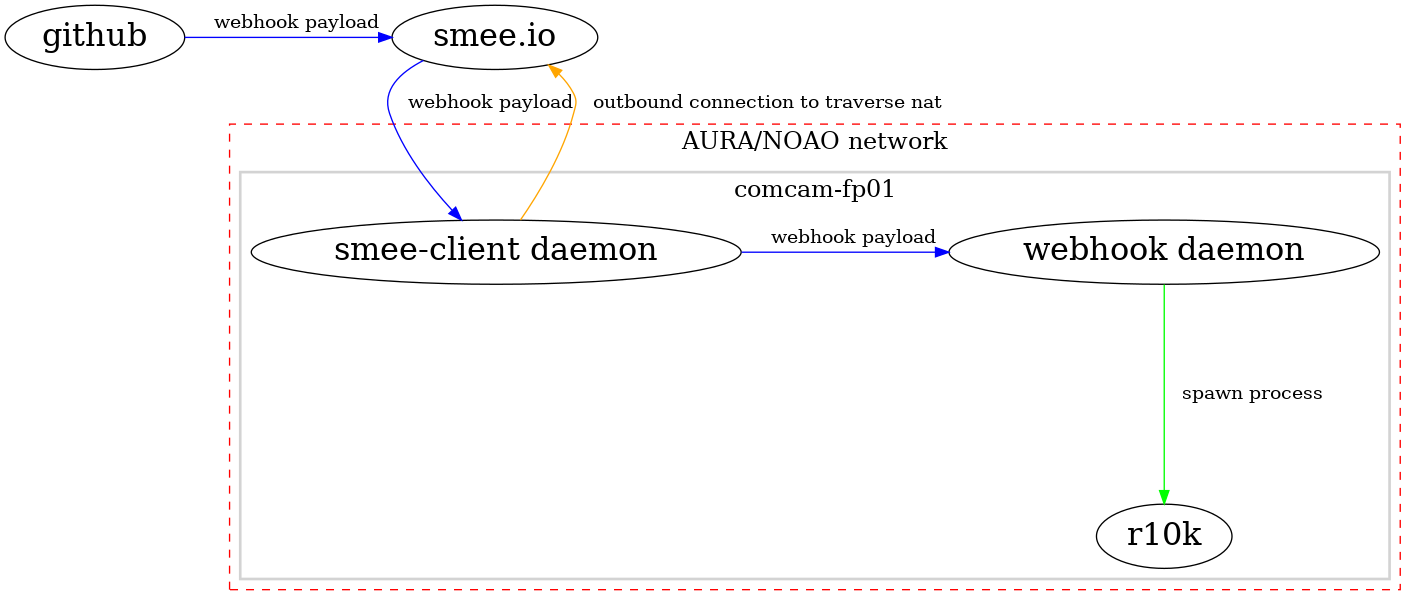
Our proof of concept implementation uses github webhooks on the lsst-it/lsst-itconf and lsst-it/lsst-puppet-hiera* repos that push to smee.io. A simple smee-client daemon is running on the foreman host. smee-client open a persistent outbound connection to smee.io and thus is able to traverse NAT and stateful firewalls. smee-client receives push notifications of the webhook payload, which is then passed onto the webhook service that is bundled with the puppet/r10k module. The webhook service parses the branch name out of the payload and triggers r10k to update only that branch (regaurdless of the source repo name).
In addition, r10k is triggered from cron to update all environments every 30 minutes to prevent desync if the smee-client outbound connect is broken, or a notification is lost.
3.5 Misc frustrations¶
- DNS
- no central auth
3.6 TODO¶
- doc or puppetize foreman install/bootstrap
- develop hammer (cli) or psql scripts to allow boot strapping a foreman install without requiring manual configuration
- resolve ipmitool/lanplus not being able to communicate with idrac IPMIv2 implementation
- Dell UEFI firmware boots extremely slowly… see if this can be speed up by disabling boot device probing on PCIe slot which show not be booted from.
- Find a replacement for the puppetlabs agent module as it is strangely inflexible
- disable ipv6
- investigate uefi boot order magically changing to put the perc control first; needs to be set to pxe (pref. by ipmi) for foreman to reprovision a node
- the r10k/smee webhook proxying should be replaced with a more production appropriate system. There are examples of webhook -> aws api gateway -> lambda -> sns.
- configure smartd/megacli/perccli to monitor lsi raid controller attached drives